Measurement & mixed states for quantum systems.
Notes on measurement for quantum systems.
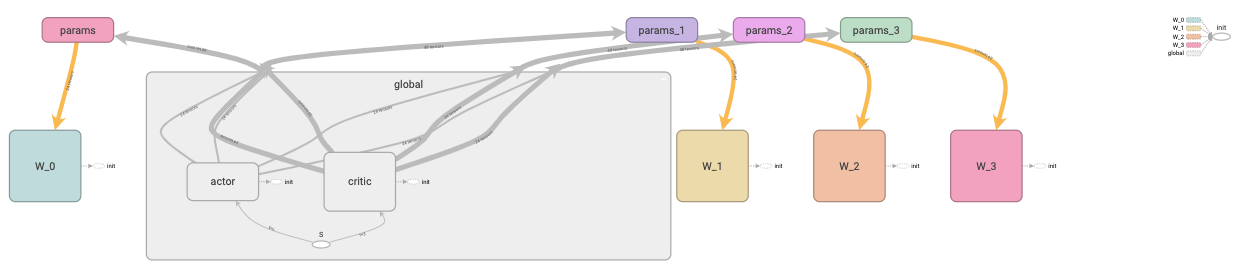
This post documents my implementation of the A3C (Asynchronous Advantage Actor Critic) algorithm. (multi-threaded continuous version)
An A3C (Asynchronous Advantage Actor Critic) implementation with Tensorflow. This is a multi-threaded continuous version. The code is tested with Gym’s continuous action space environment, Pendulum-v0 on Colab.
Code on my Github: (use maximum terms possible)
If Github is not loading the Jupyter notebook, a known Github issue, click here to view the notebook on Jupyter’s nbviewer.
The majority of the code is very similar to the discrete version with the exceptions highlighted in the implementation details section:
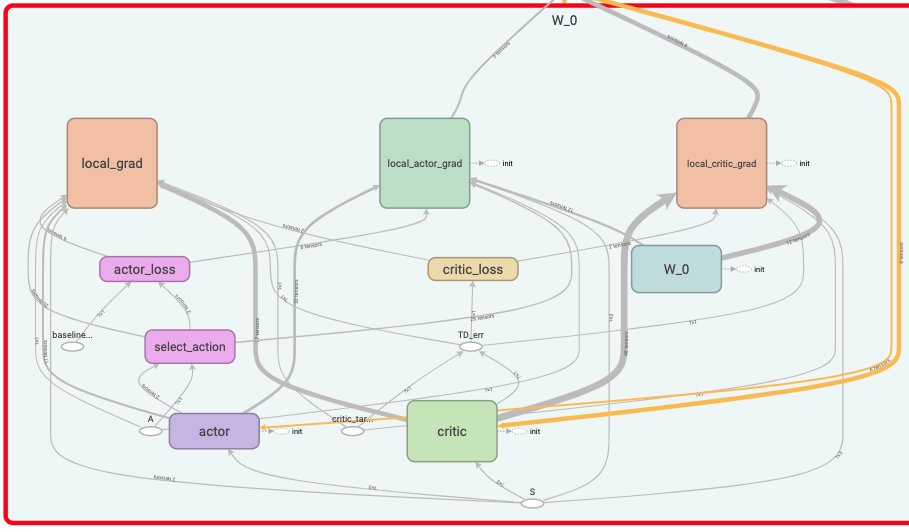
Action selection:
with tf.name_scope('select_action'):
#mean = mean * action_bound[1]
mean = mean * ( action_bound[1] - action_bound[0] ) / 2
sigma += 1e-4
normal_dist = tf.distributions.Normal(mean, sigma)
self.choose_a = tf.clip_by_value(tf.squeeze(normal_dist.sample(1), axis=[0, 1]), action_bound[0], action_bound[1])
Loss function of the actor network:
with tf.name_scope('actor_loss'):
log_prob = normal_dist.log_prob(self.a)
#actor_component = log_prob * tf.stop_gradient(TD_err)
actor_component = log_prob * tf.stop_gradient(self.baselined_returns)
entropy = -tf.reduce_mean(normal_dist.entropy()) # Compute the differential entropy of the multivariate normal.
self.actor_loss = -tf.reduce_mean( ENTROPY_BETA * entropy + actor_component)
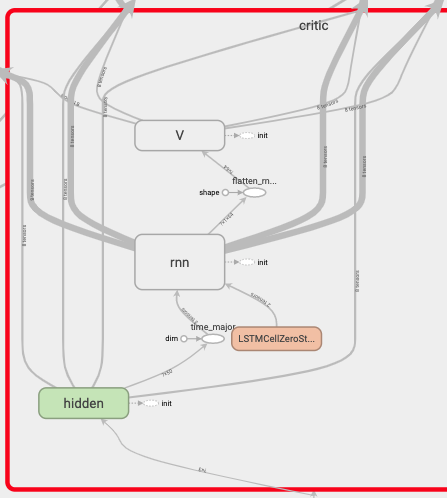
The following code segment creates a LSTM layer:
def _lstm(self, Inputs, cell_size):
# [time_step, feature] => [time_step, batch, feature]
s = tf.expand_dims(Inputs, axis=1, name='time_major')
lstm_cell = tf.nn.rnn_cell.LSTMCell(cell_size)
self.init_state = lstm_cell.zero_state(batch_size=1, dtype=tf.float32)
outputs, self.final_state = tf.nn.dynamic_rnn(cell=lstm_cell, inputs=s, initial_state=self.init_state, time_major=True)
# joined state representation
lstm_out = tf.reshape(outputs, [-1, cell_size], name='flatten_rnn_outputs')
return lstm_out
The following function in the ACNet class creates the actor and critic’s neural networks(note that the critic’s network contains a LSTM layer):
def _create_net(self, scope):
w_init = tf.glorot_uniform_initializer()
#w_init = tf.random_normal_initializer(0., .1)
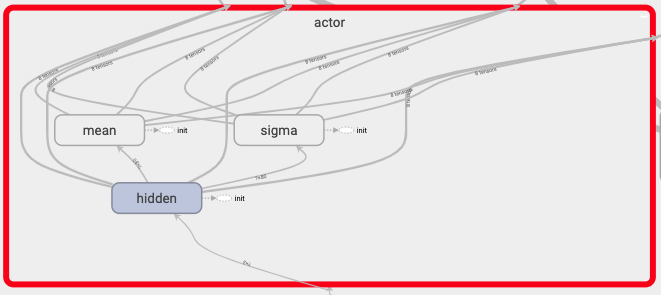
with tf.variable_scope('actor'):
hidden = tf.layers.dense(self.s, actor_hidden, tf.nn.relu6, kernel_initializer=w_init, name='hidden')
#lstm_out = self._lstm(hidden, cell_size)
# tanh range = [-1,1]
mean = tf.layers.dense(hidden, num_actions, tf.nn.tanh, kernel_initializer=w_init, name='mean')
# softplus range = {0,inf}
sigma = tf.layers.dense(hidden, num_actions, tf.nn.softplus, kernel_initializer=w_init, name='sigma')
with tf.variable_scope('critic'):
hidden = tf.layers.dense(self.s, critic_hidden, tf.nn.relu6, kernel_initializer=w_init, name='hidden')
lstm_out = self._lstm(hidden, cell_size)
V = tf.layers.dense(lstm_out, 1, kernel_initializer=w_init, name='V')
actor_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/actor')
critic_params = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope=scope + '/critic')
return mean, sigma, V, actor_params, critic_params
Notes on measurement for quantum systems.
Notes on quantum states as a generalization of classical probabilities.
The location of ray_results folder in colab when using RLlib &/or tune.
My attempt to implement a water down version of PBT (Population based training) for MARL (Multi-agent reinforcement learning).
Ray (0.8.2) RLlib trainer common config from:
How to calculate dimension of output from a convolution layer?
Changing Google drive directory in Colab.
Notes on the probability for linear regression (Bayesian)
Notes on the math for RNN back propagation through time(BPTT), part 2. The 1st derivative of \(h_t\) with respect to \(h_{t-1}\).
Notes on the math for RNN back propagation through time(BPTT).
Filter rows with same column values in a Pandas dataframe.
Building & testing custom Sagemaker RL container.
Demo setup for simple (reinforcement learning) custom environment in Sagemaker. This example uses Proximal Policy Optimization with Ray (RLlib).
Basic workflow of testing a Django & Postgres web app with Travis (continuous integration) & deployment to Heroku (continuous deployment).
Basic workflow of testing a dockerized Django & Postgres web app with Travis (continuous integration) & deployment to Heroku (continuous deployment).
Introducing a delay to allow proper connection between dockerized Postgres & Django web app in Travis CI.
Creating & seeding a random policy class in RLlib.
A custom MARL (multi-agent reinforcement learning) environment where multiple agents trade against one another in a CDA (continuous double auction).
This post demonstrate how setup & access Tensorflow graphs.
This post demonstrates how to create customized functions to bundle commands in a .bash_profile file on Mac.
This post documents my implementation of the Random Network Distillation (RND) with Proximal Policy Optimization (PPO) algorithm. (continuous version)
This post documents my implementation of the Distributed Proximal Policy Optimization (Distributed PPO or DPPO) algorithm. (Distributed continuous version)
This post documents my implementation of the A3C (Asynchronous Advantage Actor Critic) algorithm (Distributed discrete version).
This post documents my implementation of the A3C (Asynchronous Advantage Actor Critic) algorithm. (multi-threaded continuous version)
This post documents my implementation of the A3C (Asynchronous Advantage Actor Critic) algorithm (discrete). (multi-threaded discrete version)
This post demonstrates how to accumulate gradients with Tensorflow.
This post demonstrates a simple usage example of distributed Tensorflow with Python multiprocessing package.
This post documents my implementation of the N-step Q-values estimation algorithm.
This post demonstrates how to use the Python’s multiprocessing package to achieve parallel data generation.
This post provides a simple usage examples for common Numpy array manipulation.
This post documents my implementation of the Dueling Double Deep Q Network with Priority Experience Replay (Duel DDQN with PER) algorithm.
This post documents my implementation of the Dueling Double Deep Q Network (Dueling DDQN) algorithm.
This post documents my implementation of the Double Deep Q Network (DDQN) algorithm.
This post documents my implementation of the Deep Q Network (DQN) algorithm.